Resnet 详解
ResNet
参考链接:
你必须要知道CNN模型:ResNet
梯度消失和梯度爆炸及解决方法
深层网络的退化问题
深层网络结构为什么会导致模型退化?
网络的深度对于模型特征提取至关重要,按理来说,不断堆叠网络层数,模型可以进行更加复杂的特征模式提取,因此模型深度越深,就能取得更好的结果。但事实上,当网络深度增加到一定程度后,网络准确度出现了饱和,甚至出现下降,即网络退化(Degradation problem),网络退化的原因主要是由梯度消失或者梯度爆炸造成的。什么是梯度消失?什么是梯度爆炸?
目前优化神经网络的方法都是根据损失函数计算的误差通过梯度反向传播的方式(即BP),指导深度网络权值的更新优化。其中将误差从末层往前传递的过程需要链式法则(Chain Rule), 而链式法则是一个连乘的形式,梯度将以指数形式传播。随着网络深度不断增加,在根据损失函数计算的误差通过梯度反向传播的方式对深度网络权值进行更新时,容易导致得到的梯度值接近0或特别大,也就是梯度消失或爆炸。反向传播即链式法则如下图所示,梯度值为学习率右侧的偏导求值,当导数部分小于1时,经过链式法则连乘不断放大,最终梯度值会接近于0,模型几乎不再更新,即梯度消失,若导数部分大于1,经过链式法则连乘,最终梯度值会越来越大,发生梯度爆炸。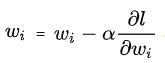
梯度消失/梯度爆炸解决方法
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。解决梯度消失、爆炸主要有以下几种方法:
- 梯度剪切:主要是针对梯度爆炸,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
- 权重正则化:通过对网络权重做正则来限制过拟合。如果发生梯度爆炸,那么权值就会变的非常大,反过来,通过正则化项来限制权重的大小,也可以在一定程度上防止梯度爆炸的发生。
- 选择ReLU代替Sigmoid作为激活函数:使用sigmoid作为损失函数,其梯度是不可能超过0.25的,这样经过链式求导之后,很容易发生梯度消失(即越乘越小),同理,tanh作为损失函数,它的倒数仍然是小于1。relu函数的导数在正数部分是恒等于1的,因此在深层网络中使用relu激活函数就不会导致梯度消失和爆炸的问题。
- batch normalization:通过对每一层的输出规范为均值和方差一致的方法,消除了权重参数放大缩小带来的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输出从饱和区拉倒了非饱和区。
- 残差网络(ResNet)
- LSTM门结构
ResNet
恒等映射
假设现在存在一个浅层网络,为了获得更好地学习能力,你想通过向上堆积新层的方式来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,不应该出现退化现象,但是显然事实如刚才所说,存在梯度爆炸或梯度消失的现象,那么残差网络单元是如何解决这一问题的呢?
残差单元
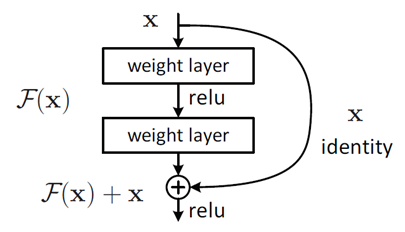
如图为残差网络ResNet的一个残差学习单元
原先当输入为$x$时,其对应输出的特征为$H(x)$,而残差学习单元将学习的目标转化为了对残差$F(x)=H(x)-x$的学习,最终输出的仍是$H(x)$,只是输出从原有的$x$变为了$x+F(x)$。
为什么要这样做?之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射(即$H(x)=x+0$),至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。
ResNet采用的两种残差单元
浅层残差单元
对于短路连接,当输入和输出维度一致时,可以直接将输入加到输出上。但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。有两种策略:(1)采用zero-padding增加维度,此时一般要先做一个downsamp,可以采用strde=2的pooling,这样不会增加参数;(2)采用新的映射(projection shortcut),一般采用1x1的卷积,这样会增加参数,也会增加计算量。短路连接除了直接使用恒等映射,当然都可以采用projection shortcut。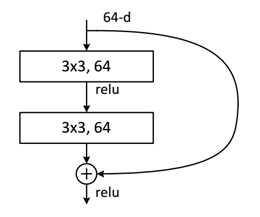
如图,输入维度为64维,内部经过2个3*3,深度为64的卷积核对残差进行学习,用relu激活函数(原因参照上面陈述)进行非线性激活。(可以理解为将外部$x$的学习转化为内部残差$F(x)$的学习)。
深层残差单元
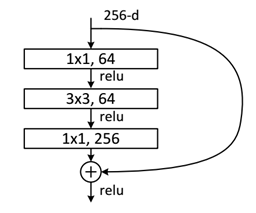
如图,输入维度为256维,用 $1\times1$ 卷积核下采样,将深度降为64维,经过 $3\times3$ 卷积核对残差进行内部学习,再通过 $1\times1$ 卷积将维度还原到与输入维度一致,做相加操作。
补充
最近看到一篇关于 ResNet 的知乎讲解很有意思,讲得非常透彻,特此安利一下:Resnet到底在解决一个什么问题呢?
关于里面一些有趣的点,做一下总结:
- 什么造成了模型退化?
模型退化现象:当神经网络的层数堆叠到一定程度时,模型的效果不升反降。
起初人们认为是模型过拟合导致的 (模型性能不佳,存在高偏差,导致欠拟合;模型复杂度过高,存在高方差,导致过拟合),但是很明显当前CNN面临的效果退化不是因为过拟合,因为过拟合的现象是”高方差,低偏差”,即测试误差大而训练误差小。但实际上,深层CNN的训练误差和测试误差都很大。
那么是否与模型梯度爆炸/梯度消失有关?作者首先介绍了一些反向传播的知识,很通俗易懂,可以仔细研读一下(Resnet到底在解决一个什么问题呢?)。在反向传播中,其输出值的大小除了与求导式子有关外,很大程度上还取决于输入值的大小,当输入值大于1时,经过反向传播多层的回传,梯度将以几何倍数增长 (涉及了链式求导的知识),这就造成了深度神经网络梯度爆炸的现象,同理当输入值小于1时,会造成梯度消失的现象。
好像是梯度爆炸/消失造成的,可事实真的如此吗?我们知道在 Resnet 前,人们处理梯度爆炸/消失时,通常用的是 Batch Normalization,理论上梯度爆炸/消失很早就被人们解决一大半了,为什么还是会导致模型退化呢? - 模型退化不符合常理?
按理说,当我们堆叠一个模型时,理所当然的会认为效果会越堆越好。因为,假设一个比较浅的网络已经可以达到不错的效果,那么即使之后堆上去的网络什么也不做,模型的效果也不会变差。然而事实上,这却是问题所在。“什么都不做”恰好是当前神经网络最难做到的东西之一。不断堆叠神经网络层数,会导致神经网络在具有无限可能的“非线性”道路上越走越远,以至于模型走了很远后,忘记了它为什么要出发,拟合的目标是什么 (“不忘初心,牢记使命”诚不欺我)。因此,后续就有了 Resnet 的提出,其初衷就是让模型的内部结构至少有恒等映射的能力。以保证在堆叠网络的过程中,网络至少不会因为继续堆叠而产生退化! - Resnet 的恒等映射
让深层神经网络模型具备恒等映射 $H(x)=x$是一件看似简单,但难以解决的事,此处$x$表示输入,$H(x)$对应模型学习后的输出,在上述说到,模型总会尝试着输出一点新的东西,这就导致$H(x)$和$x$不会相等。但如果把网络设计为$H(x) = F(x) + x$,即直接把恒等映射作为网络的一部分,就可以把问题转化为学习一个残差函数$F(x) = H(x) - x$。因为只要$F(x)=0$,就构成了一个恒等映射$H(x) = x$。 而且,拟合残差至少比拟合恒等映射容易得多,该结构被称为 Residual Block。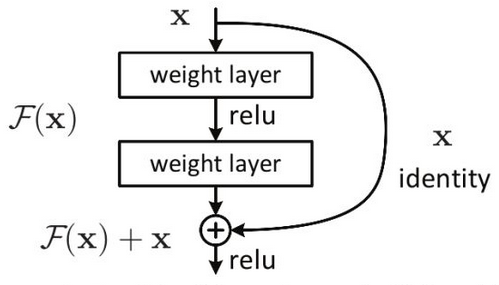
图中右侧的曲线叫做跳接(shortcut connection),通过跳接在激活函数前,将上一层(或几层)之前的输出与本层计算的输出相加,将求和的结果输入到激活函数中做为本层的输出。数学公式表达如图所示: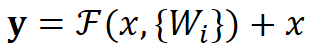
其中 $F(x,{W_i})$ 是我们学习的目标,即输出输入的残差。以上图为例,残差部分是中间有一个Relu激活的双层权重,为什么一个 Block 中要用两层的权重来表示呢?因为只用一层权重,通过公式计算就会得到以下情况,结果就是加与不加残差块没有差别。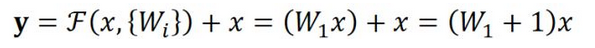
- Resnet 在 VGG 上的变化,即网络结构和一些细节
图结构可见Resnet到底在解决一个什么问题呢?
这里主要对空间维度不一致和深度不一致做一个解释。
空间维度不一致的解决方法:在跳接的部分给输入x加上一个线性映射,具体如图。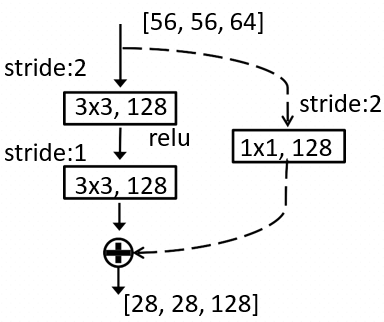
深度维度不一致的解决方法:一种是在跳接过程中加一个 $1\times1$ 的卷积层进行升维,另一种则是直接简单粗暴地补零。事实证明两种方法都行得通。通过 $1\times1$ 卷积升维的方式如图。该结构也被称为是 bottleneck,它通过使用1x1 conv来巧妙地缩减或扩张feature map维度从而使得我们的3x3 conv的filters数目不受外界即上一层输入的影响,除了改变深度维度外,它还节省了计算时间进而缩小整个模型训练所需的时间。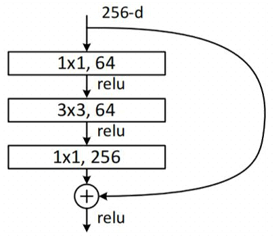
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!